
GitHub Actions 如何使用缓存
前言
在之前的文章中 《github-actions入门》《 如何使用Github Action 自动 lerna publish 》中,介绍了 Github Actions 的一些用法,其中在构建过程中,会安装很多第三方依赖,而这些依赖会很耗时,因此可以考虑是否有优化的空间,并不需要每次都重新下载,而是可以将这些依赖缓存起来,加快构建速度。
这里专门开一篇文章,来记录 Github Actions 的缓存优化相关的知识。
Cache
在构建过程中,进行缓存,加快构建速度。
主要使用action/cache。
原理
缓存大致原理就是把目标路径打包存储下来,并记录一个唯一 key。
下次启动时,根据 key 去查找。找到了就再按路径解压开。
缓存大小限制
注意缓存有大小限制。对于免费用户,单个包不能超过 500MB,整个仓库的缓存不能超过 2G。
缓存运作流程
该action主要包含三个属性:
- path: 需要缓存的文件的路径
- key: 对缓存的文件指定的唯一表示
- restore-key: 当 key 没有命中缓存时,用于恢复缓存 key 值的有序列表
下面以node项目为例,将node_modules缓存起来。
这里只列出关键步骤:
1 | steps: |
首先使用action/cache指定path和key;
这里的key包含 OS 信息、node 版本 和 package-lock.json和package.json文件的 hash 值,通常 OS 是固定下来的;
而一旦使用了新的第三方库,package-lock.json & package.json的 hash 值就会改变,得到一个新的key;
action/cache会抛出一个cache-hit的输出,如果找到对应key的缓存,值为true。
在随后的安装步骤中,可以使用if对cache-hit做判断。如果找到缓存就跳过,否则就安装依赖。
在第一次运行时,cache 找不到,执行npm install,在随后的 post cache 步骤中对node_modules做缓存。
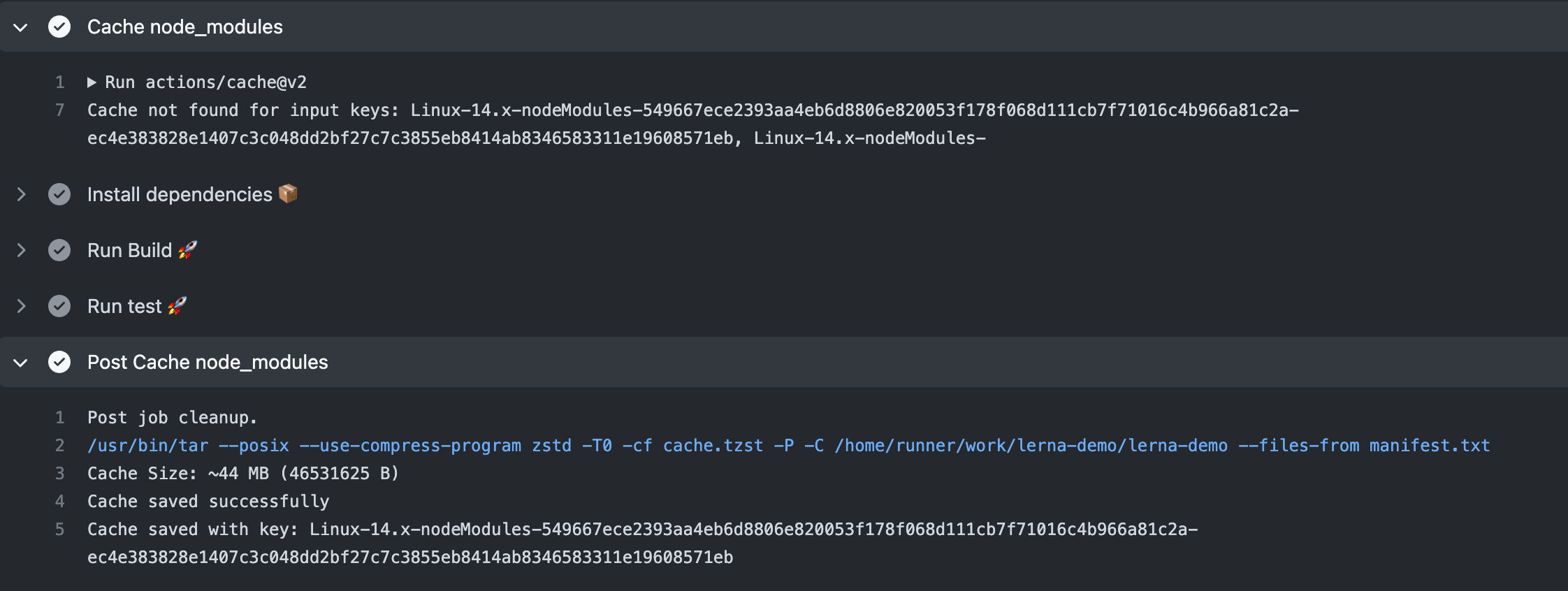
第二次运行时,找到 cache, 则跳过npm install,直接使用缓存:
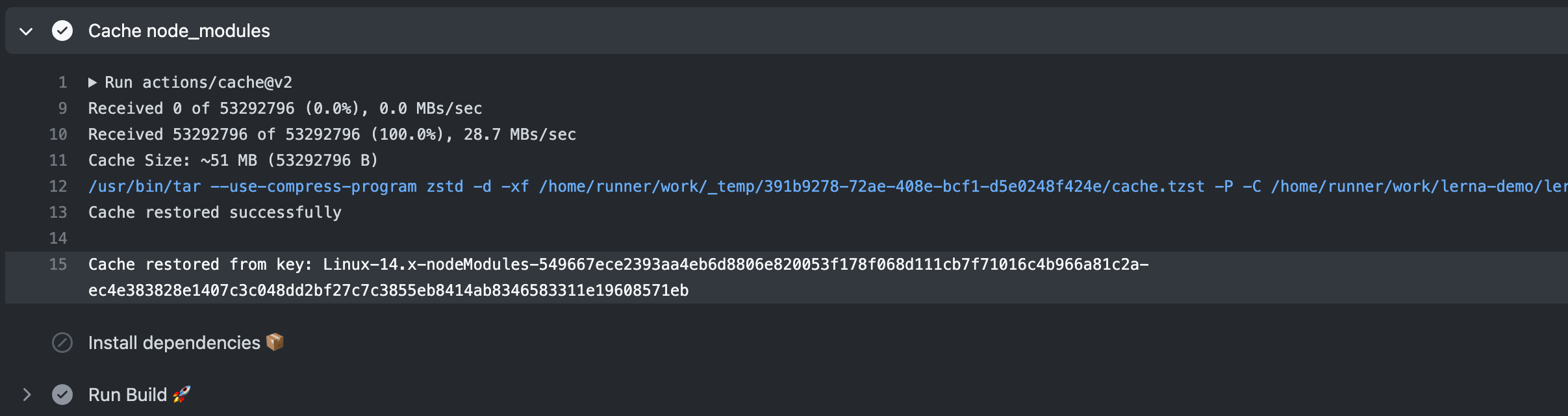
更多使用请参考官网 & actions/cache & Cache node - npm
参考链接
GitHub Actions 如何使用缓存
https://hailangya.com/articles/2021/12/17/github-actions-cache/

